MySQL中的EXPLAIN
EXPLAIN : query Execution plan,平常工作中,我们会借助 EXPLAIN 命令分析SELECT语句的执行计划,查看使用到的索引,扫描的行数,来优化我们的查询。
EXPLAIN 包含的信息大致有select_type,table,partitions(5.7),type,key,extra等十余列,下面将会对其中出现的某些列,进行具体分析。如无特殊说明,本文章所指的MySQL版本皆为5.7.24。
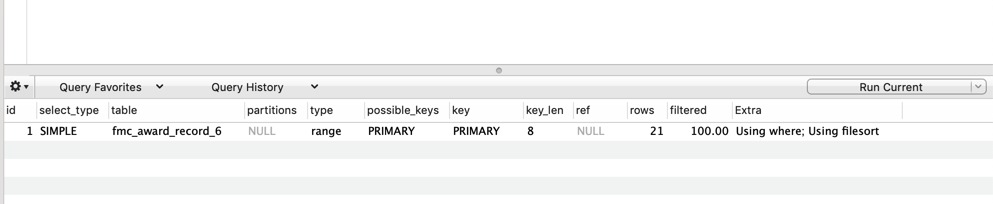
select_type
select_type:表示查询类型,常见的查询类型有
- simple:最简单的select查询,不使用子查询或者union
- primary:复杂查询中,最外面的那层查询
- union:union查询中,第二个/后面的select语句
- union result:表示union查询的结果
- subquery:子查询中的第一个select
- dependent union:union中的第二个select语句,但查询结果依赖于外面的查询
- dependet subquery:子查询中的第一个select,但查询结果依赖于外面的查询
- driverd:派生表(select xxx as a)
partitions
使用的哪些分区,MySQL5.7中会默认显示,如果没有使用分区,则展示为NULL。
MySQL中的分区,是数据库层面的分表。而像sharding-jdbc这类的方案,是应用层上的分库分表。MySQL现在支持的分区类型包括:RANGE、LIST、HASH、KEY四种方式。除了这四种分区以外,MySQL还支持基于分区表的基础上继续分区–子分区(subpartitions)。
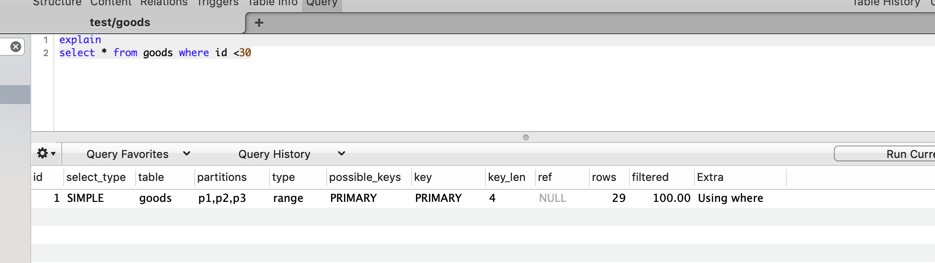
支持指定分区查询
select * from goods3 partition(p1) where id <10
MySQL关于partition的相关官方文档:https://dev.mysql.com/doc/refman/5.7/en/partitioning-types.html
RANGE分区
按照给定的范围分区,例如按id大小分区,小于10的为p1,小于20的为p2,其他的为p3。不使用COLUMNS关键字的话,RANGE括号内字段必须是整数(整数的字段或者UNIX_TIMESTAMP(date_created)这类返回整数的函数)。
CREATE TABLE `goods1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uname` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY RANGE (id)
(PARTITION p1 VALUES LESS THAN (10) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (20) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
查询时,以id<30为查询条件,则partitions命中p1,p2,p3三个分区。
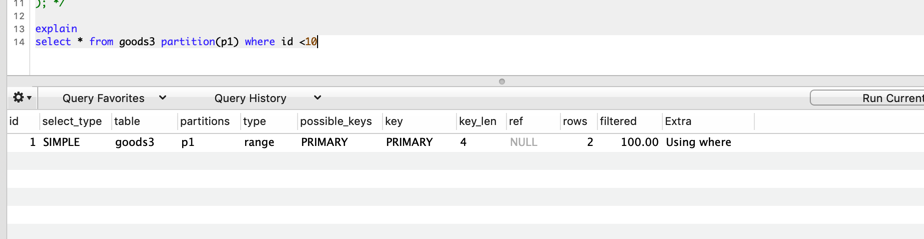
List分区
List分区和RANGE分区类似,区别在于RANGE是按范围区间,而List则是基于一系列值给出的特定枚举。不使用COLUMNS关键字的话,LIST括号内字段必须是整数(整数的字段或者UNIX_TIMESTAMP(date_created)这类返回整数的函数)。
CREATE TABLE `goods3` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uname` char(10) DEFAULT NULL,
`goods_status` tinyint(4) DEFAULT 0,
PRIMARY KEY (`id`,`goods_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY LIST (goods_status)(
PARTITION p1 VALUES in (0),
PARTITION p2 VALUES in (1),
PARTITION p3 VALUES in (2),
PARTITION p4 VALUES in (3)
); */
例如,goods3 表,按照status分区,将goods表4分位四个分区。插入数据时,如果goods_status不在分区的取值(0,1,2,3)中,会报错。查询的时候,可以指定partition(partition_name)分区名称来查询指定分区的数据。
Hash分区
Hash分区,基于给定的分区个数,把取模操作将数据分配到不同的分区中。分区名称:p0,p1,p2…
CREATE TABLE `goods4` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uname` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY hash (id) partitions 4;*/
由于分区在创建表的时候设置好了,如果要新增/缩减分区,需要迁移的数据量将会很大。
MySQL还提供了Linear Hash的分区方式,它和Hash函数不同的地方时,它不是按照mod函数计算,而是基于另一种算法,关于linear hash,可以参考官方文档的内容。
Linear Hash的优点是:在处理tb级数据时,增加、删除、合并和拆分分区会更快。缺点是:相对于Hash分区,数据分布不均匀的概率更大。
Key分区
Key分区和Hash分区类似,不过使用的分区函数是MD5,所以Key分区支持除Text和BLOB之外的所有数据类型的分区,而Hash分区只支持数字类型的分区。
CREATE TABLE `goods5` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uname` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*!50100 PARTITION BY key (id) partitions 4;*/ ;
和Hash分区类似,Key分区也支持线性Key分区(Linear Key),概念和Hash分区中的LINEAR HASH一样。
type
type的官方定义是”access_type”:访问类型。性能从高到低有: system, const, eq_ref, ref, fulltext, ref_or_null, index_merge, unique_subquery, index_subquery, range, index, ALL。下面是几个常见的access_type的具体解释。
const
表中至多有一个匹配的行,常用于匹配 primary key 或者 unique索引。
eq_ref
表示前表查询的结果,只能匹配到后表一行结果,和const、system不同的是,多出现在join中,且使用到了主键索引,或者非空的unqiue索引。
ref
和eq_ref类似,也是出现在join操作中。区别在于,eq_ref针对的是唯一匹配,ref也可以用于index列进行=和<=>比较操作。
unique_subquery、index_subquery
unique_subquery:在in的子查询里面,用到了等价于eq_ref的索引
index_subquery:在in的子查询里面,用到了等价于ref的索引
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
使用索引进行范围类型查询,如>, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN() 等操作
index
表示全表扫描索引,和ALL类似,只不过ALL是全表扫瞄,index是扫描的是索引。
ALL
表示全表扫描, 查询性能最差的查询之一,也是要重点优化的查询。
possible_keys和Key
possible_keys 指出MySQL在查询记录过程中,能够使用到的索引。key 字段表示当前查询实际用到的字段。
即使有些索引在 possible_keys 中列出了,但是并不意味着 key 中一定会选择这个索引。
如果没有使用索引,则 key 字段显示为null。
ref、rows、filtered
ref:用来标识那些和索引比较的列或者常量
rows:rows列表示MySQL执行查询需要检查的行数。对于InnoDB引擎来说,rows是一个估算值,并不是确切值。
filtered:5.7版本默认显示,表示涉及到的row中过滤出来的行数。rows × filtered 表示多少行数据过滤出来与之前的表关联。
extra
MySQL执行查询过程中的一些额外信息,也是我们分析时非常重要的一个字段。MySQL官方文档上有这样一段话:
If you want to make your queries as fast as possible, look out for
Extracolumn values ofUsing filesortandUsing temporary, or, in JSON-formattedEXPLAINoutput, forusing_filesortandusing_temporary_tableproperties equal totrue.
所以extra对我们的查询优化来说,非常重要。要尤其注意 Using filesort 或者 Using temporary 这样的查询。
extra可能出现的值很多,详细可以查询官方文档:https://dev.mysql.com/doc/refman/5.6/en/explain-output.html#explain-extra-information。下面是其中常见的几个的值。
Using index
表示直接从索引树中获取的信息,而不用回表查询。
Using Where
A
WHEREclause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if theExtravalue is notUsing whereand the table join type isALLorindex.
where子句用来限制匹配到下一个表的记录或者发送到client的记录。如果查询过程中 Extra 没有Using where,且 type 不是 ALL 或着 index,除非你是想全表扫描,否则的话,这个sql是肯定需要优化的。
Using where 表示存储引擎检索行记录后,对不能在索引中就进行 where 条件过滤的进行再过滤。
Using index condition
MySQL5.6引入的新特性:Index Condition Pushdown (ICP),先在存储引擎层对索引进行条件过滤。
ICP只能用于二级索引,不能用于主索引。对于WHERE条件中,不在索引中的列,还是只能到Server端做WHERE条件过滤(Using where)。
CREATE TABLE `demo_user` (
`user_id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`gmt_create` timestamp NULL DEFAULT NULL,
`gmt_modified` timestamp NULL DEFAULT NULL,
`name` varchar(11) DEFAULT NULL,
`cert_no` bigint(11) DEFAULT NULL,
`password` bigint(11) DEFAULT NULL,
`sex` tinyint(4) DEFAULT NULL,
`is_verify` tinyint(4) DEFAULT NULL,
`is_deleted` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`user_id`),
KEY `idx_cert_no` (`cert_no`)
) ENGINE=InnoDB AUTO_INCREMENT=393213 DEFAULT CHARSET=utf8mb4;
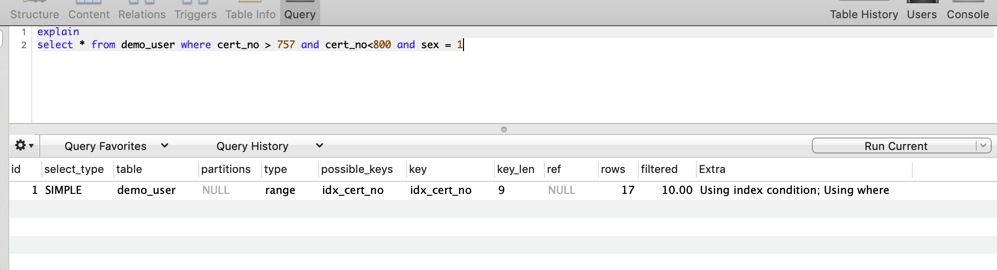
以 demo_user 表为例,我们以 cert_no 为条件进行查询,因为cert_no有我们的 idx_cert_no ,所以 Extra 打印出了 Using index condition。
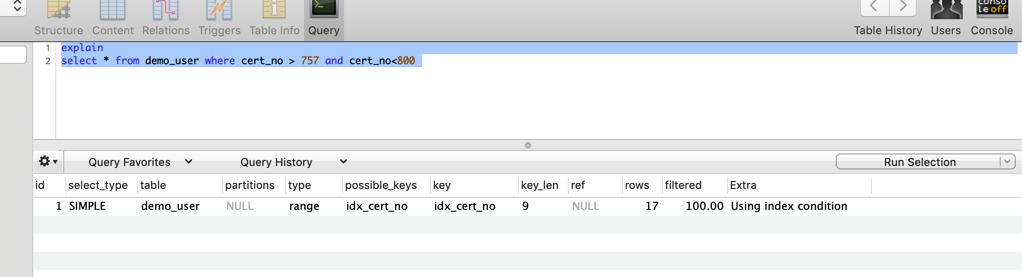
因为sex字段不在索引列中,所以MySQL现在存储引擎层,根据cert_no的条件对数据做了第一次过滤( Using index condition )。在Server层对数据做了 sex = 1 的过滤。在我们这个例子中,rows = 17 实际上是根据 idx_cert_no 匹配到的值,而 sex= 1 会在过滤掉一条,所以实际查询到的数据是16条。
Using temporary
MySQL为了得到最终查询结果,创建了一个临时表。这种情况在 GROUP BY 和 ORDER BY 语句中经常出现。
这是一个比较耗时的操作,也是我们优化sql中的重点关注对象。
Using filesort
Using filesort是表明需要进行排序操作,而并不是一定会使用文件进行排序。MySQL有一个 sort_buffer_size 阈值,在未超过这个值的前提下进行的是内存排序,超过的话会使用外部文件排序。
filesort只会作用于单表上,如果多个表的数据需要进行排序,那么MySQL会先使用 Using temporary 创建临时表保存临时数据,再在临时表上使用 Using filesort 进行排序。