Java中的NIO
Java中的几种常见的IO模型
同步和异步
- 同步:调用者请求被调用者,当一个调用发出后,需要等待返回消息(用户线程不断去询问),才可以执行后续
- 异步:调用者请求被调用者,当一个调用发出后,调用者不需要等待返回消息,请求处理完成后会通过回调来通知调用者。
阻塞和非阻塞
- 阻塞:当前线程不断轮询结果,知道结果返回
- 非阻塞:会立即返回(虽然还没得到结果),不会阻塞当前线程。
Java最开始提供的IO模型是传统的BIO(Block IO),它是同步阻塞的IO模型。BIO的效率是比较低下的,所以后面又出现了BIO的改进版本-伪异步 IO。
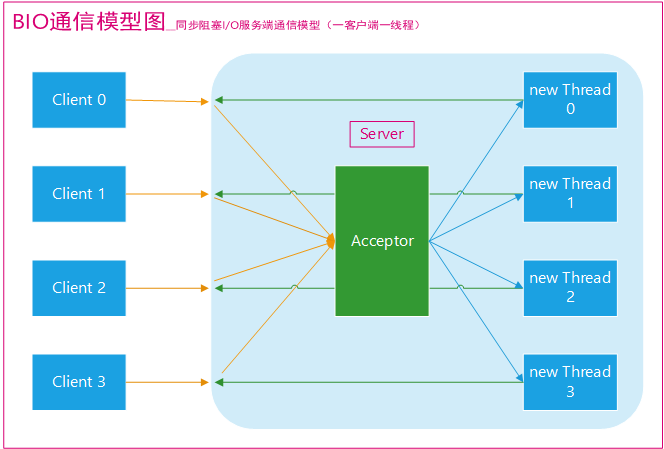
传统BIO BIO的本质就是一个client对应一个server的处理线程。当server接受到一个client的请求后,会为其创建一个线程进行处理,处理完成后,通过输出流将结果返回给client,并将server的线程销毁。
这个模型的缺点就是,线程是非常宝贵的计算机资源,一来,线程创建和销毁是重量级的系统函数;再者线程需要占用一定的内存空间,Java中线程栈一般会分配512k-1m的空间。创建过多的线程,会吃掉过来的JVM内存。同时,线程之间的切换,对CPU而言,也意味着不小的开销。
伪异步IO
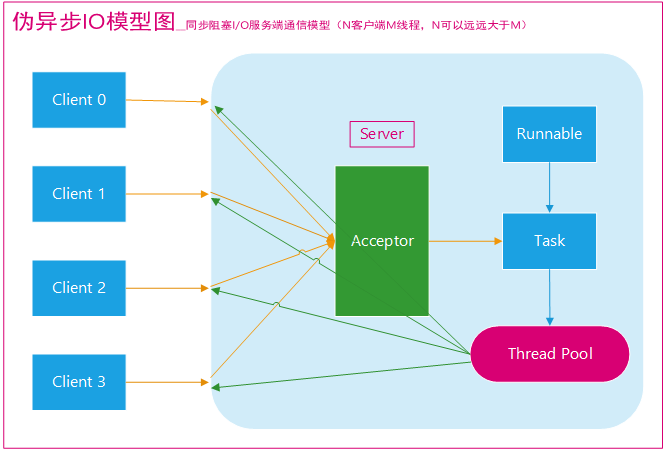
为了改进传统BIO一对一的IO模型,又演化出了一种通过线程池,一个线程池处理所有client的模型。这样,避免了频繁的线程创建和销毁,在client连接数不是很高的情况,还是可以比较好的支持的,线程池还起到了限流的作用。但是如果client连接数很高,可能server并不能处理所有client的请求。
NIO(New IO) 在JDK1.4中引入了NIO框架,在NIO中有三个很重要的概念:
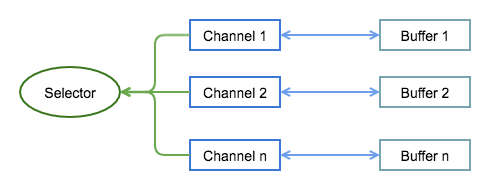
- 缓冲区
Buffer:本质上就是一个数组,包含一些要读写的数据 - 通道
Channel:通过通道来读写数据 - 多路复用器
Selector:用于选择已经就绪的任务,selector 会轮询注册在其上的 channel,选出已经就绪的 channel。
和BIO相比,BIO是阻塞式的,而NIO是非阻塞的(?)。BIO面向流的(Stream),而NIO面向缓冲区(Buffer)。
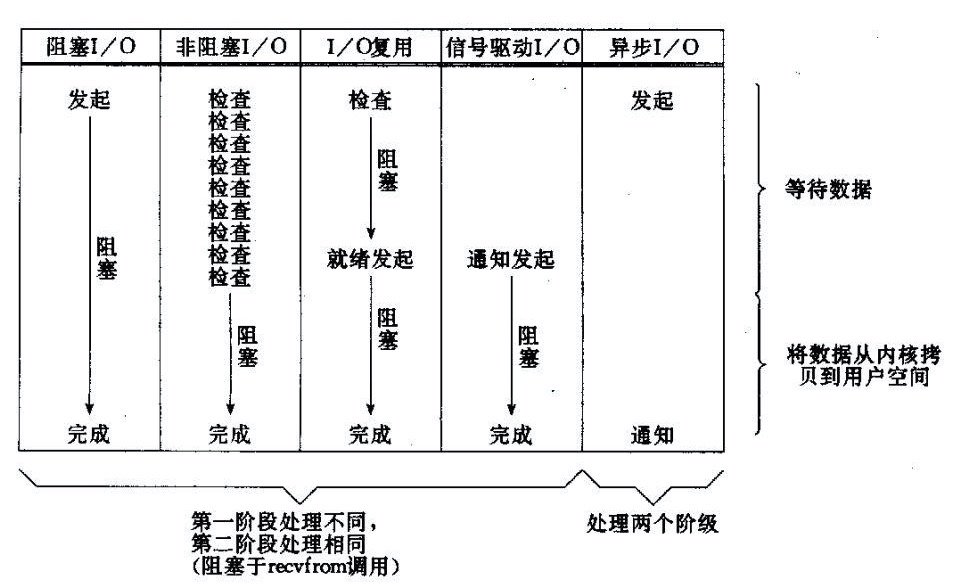
在Linux(UNIX)操作系统中,共有五种IO模型,分别是:阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动IO模型以及异步IO模型。Java提供的I/O Api其实一来的还是操作系统层面的I/O实现。Linux中的几种模型详解:Linux-的-IO-多路复用模型
NIO中的几个重要概念和基本用法
Buffer
Buffer是一个对象,实质上是一个数组,占用一定的内存空间,可以用来读写数据。在NIO中,所有数据都是通过Buffer处理的。读取/写入数据时都是到Buffer中进行的。
Java中每一种基本Java类型都有对应的缓冲区类型(DoubleBuffer,LongBuffer),最常用的缓冲区类型ByteBuffer。
ByteBuffer的使用
public static void main(String[] args) {
byte[] req = "Hello World".getBytes();
ByteBuffer buffer = ByteBuffer.allocate(req.length);
buffer.put(req);
buffer.flip(); //buffer->channel
while (buffer.hasRemaining()) {
System.out.print((char) buffer.get());
}
System.out.println();
buffer.position(0); //移动到开头
while (buffer.hasRemaining()) {
System.out.print((char) buffer.get());
}
System.out.println();
buffer.clear();
byte[] req2 = "ddd".getBytes();
buffer.put(req2);
buffer.flip();
while (buffer.hasRemaining()) {
System.out.print((char) buffer.get());
}
System.out.println();
}
ByteBuffer提供了java.nio.ByteBuffer#allocate和java.nio.ByteBuffer#allocateDirect两种创建缓冲区的方式,前者分配在堆上,被gc管理和回收。后者是直接内存(也叫堆外内存),不直接控制于JVM,只能等Full GC的时候才能被回收。(direct buffer归属的的JAVA对象是在堆上且能够被GC回收的,一旦它被回收,JVM将释放direct buffer的堆外空间。)。
- 关于堆外内存的gc和
-XX:+DisableExplicitGC参数的关系参考stackoverflow相关问题:Impact of setting -XX:+DisableExplicitGC when NIO direct buffers are used - 可通过
-XX:MaxDirectMemorySize=512m参数设置JVM可用的堆外内存大小。
Channel
Java NIO中,所有的I/O操作都基于Channel对象,channel代表的是和某一实体的连接,这个实体可能是文件,socket。因为要和不同的I/O服务交互,执行不同的I/O操作,所以就会有不同的Channel实现,比如:FileChannel、SocketChannel、DatagramChannel(UDP网络通信)
值得注意的是,FileChannel只能在阻塞模式下工作。参考:Why FileChannel in Java is not non-blocking?
Selector
多个Channel注册在Selector,Selector不断轮训Channel,如果Channel上有新的TCP连接、读写时间等,这个Channel处于就绪状态。就绪的Channel会被Selector轮训出来,通过SelectorKey()函数可以获取所有就绪Channel的Set集合,通过Channel进行后续操作。
Selector可以轮训多个Channel,Linux(>=2.6)环境下JDK底层使用的是epoll,关于epoll和select参考:Unix 网络 IO 模型及 Linux 的 IO 多路复用模型、Linux下的I/O复用与epoll详解。
因为select/poll是顺序扫描file descriptor是否就绪,所以存在文件描述符限制(fd简介),而epoll是基于事件驱动方式的,这就意味着一个Selector可以负责成千上万个Channel。
todo-补习Netty去!
关于I/O多路服用模型以及Reactor模型
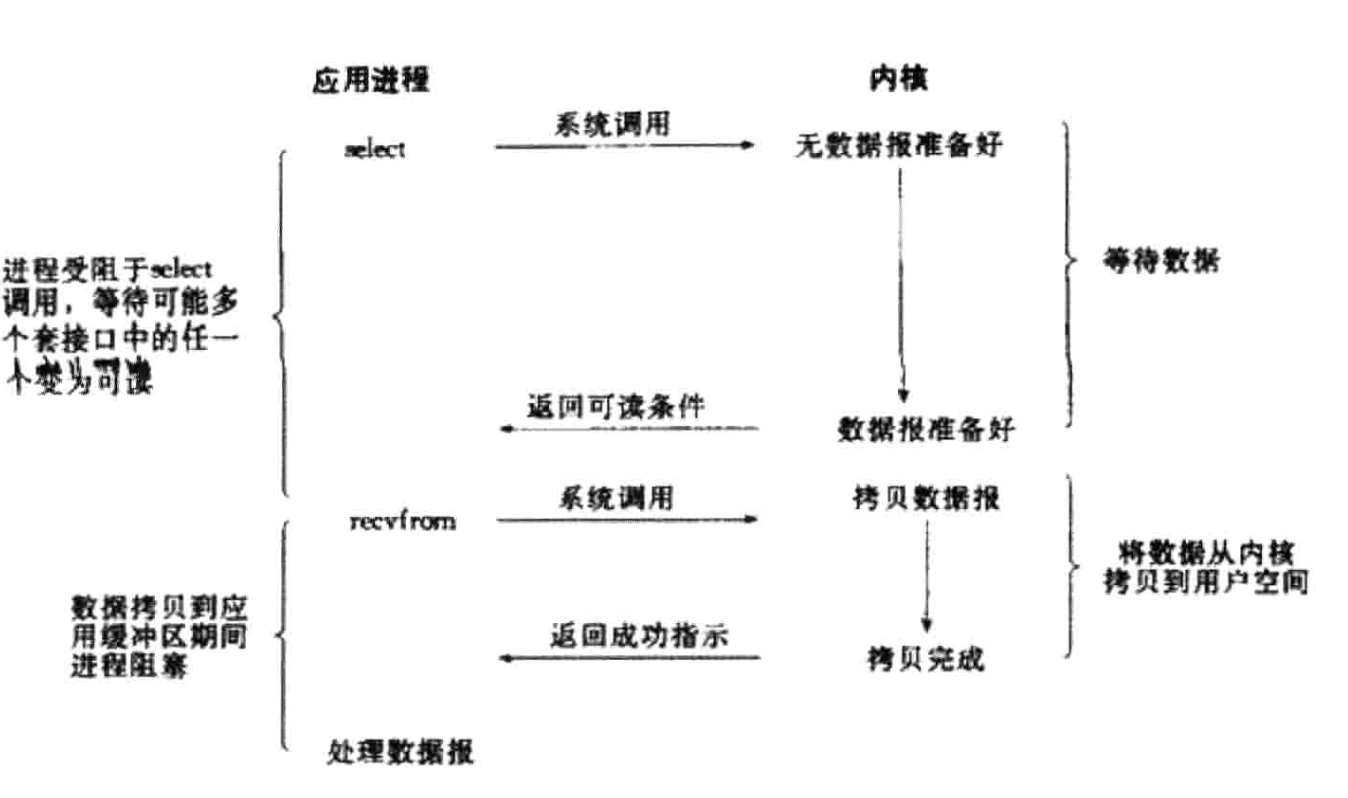
Linux中的 I/O 多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪), select/poll/epoll函数就可以返回,通知程序进行相应的读写操作。这样做的优势在于可以同时处理多个链接。
简单地说,就是多个进程的I/O注册到同一个管道上,由这一个管道统一和内核交互。当管道内的某个请求数据准备好了,进程再把对应的数据拷贝到用户空间中。IO多路复用参考资料