时间轮定时器
时间轮算法的基本架构
时间轮是基于一个循环链表(实际上就是个数组,通过下标控制)的数据结构。所以也因此得名WheelTimer。时间轮算法的复杂程度跟分级层数有关,最简单的就是一层的,复杂一点的就是分层时间轮(Hierarchical Timing Wheels)。对于一层的时间轮,添加/删除/取消任务的复杂度是O(1),过期/执行任务时,最差情况是O(n)(类似HashMap中的hash冲突,退化成链表),平均O(1)(和HashMap类似,格子越多,分散的越均匀,但是占用的空间也就越多)。
时间轮中的相关术语:
- tick:时间格,时间轮中的一格,一个格子代表一段时间;
- tickDuration: 间隔,每一格代表的时长;
- ticksPerWheel: 格数,时间轮总共有多少格.
- newTimeout: 定时任务被分配到的超时时间
时间轮上的每个tick都可以存放多个任务,并使用一个List保存tick上的任务。轮到哪个tick就执行哪个tick上的任务。任务通过取模来决定放入哪个tick。
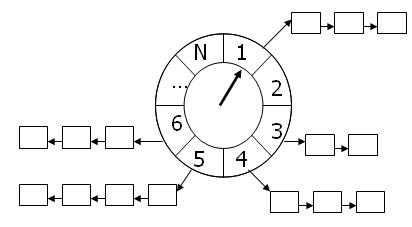
如果一个tick用时1s(tickDuration),而总共有60个tick,那么走完一圈用时差不多是60*1s。
当前指针指向的tick1,如果需要调度一个2s后需要执行的任务,那么需要等待2个tick。所以任务应该被放在第3个tick中。假设一个任务需要1min30s后执行,那么任务应该是落在指针走完后1圈后的第31个tick中。和Java中的HashMap很像(Hash散列+拉链法)。
时间轮的适用场景
当管理网络时,要对大量的连接进行超时管理,心跳检测。如果将所有连接当成一组,以定时任务的形式去管理所有的连接,肯定时不太合适的,因为此时需要的任务会非常大。
此时采用时间轮的方式,将连接分组放入到各个tick中,然后定时执行该tick中的任务。
ScheduledExecutorService和HashedWheelTimer二者侧重点不同,ScheduledExecutorService是面向任务的,当任务数量非常大时,堆(PriorityQueue)维护任务的新增、删除必然会导致性能下降。而HashedWheelTimer使用tick管理,不受任务数量的限制。
需要注意的是,一个tick中,处理任务list的是单线程的,所以可能会存在因为前一个task执行时间太久,导致后一个task实际执行时间比较晚(如果改为线程池执行,会使用大量资源,且利用率感觉也不高)。因此,HashedWheelTimer并不适合那种比较耗时的任务。
Netty中的时间轮实现
dubbo在2.7x后,在心跳检测和判断异步请求超时等场景中使用HashedWheelTimer代替了ScheduledThreadPoolExecutor,Dubbo中使用的HashedWheelTimer实际上就是Netty中的HashedWheelTimer。
下面的源码来自Dubbo 2.7.2中org.apache.dubbo.common.timer.HashedWheelTimer。
创建HashedWheelTimer实例。
/**
* tickDuration:一格的时长
* ticksPerWheel:一圈有几格
*/
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel,
long maxPendingTimeouts) {
//参数校验
if (threadFactory == null) {
throw new NullPointerException("threadFactory");
}
if (unit == null) {
throw new NullPointerException("unit");
}
if (tickDuration <= 0) {
throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
}
if (ticksPerWheel <= 0) {
throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
}
//创建时间轮(其实就是构建数组并初始化),长度为不小于ticksPerWheel的最小2的n次方
// Normalize ticksPerWheel to power of two and initialize the wheel.
wheel = createWheel(ticksPerWheel);
mask = wheel.length - 1;
// Convert tickDuration to nanos.
this.tickDuration = unit.toNanos(tickDuration);
//防止溢出,一轮的持续时间不能超过 Long.MAX_VALUE
// Prevent overflow.
if (this.tickDuration >= Long.MAX_VALUE / wheel.length) {
throw new IllegalArgumentException(String.format(
"tickDuration: %d (expected: 0 < tickDuration in nanos < %d",
tickDuration, Long.MAX_VALUE / wheel.length));
}
//创建worker线程
workerThread = threadFactory.newThread(worker);
this.maxPendingTimeouts = maxPendingTimeouts;
//控制时间轮产生的实例个数,如果产生的实例过多,打个error日志
if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&
WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {
reportTooManyInstances();
}
}
添加定时任务,调用org.apache.dubbo.common.timer.HashedWheelTimer#newTimeout方法,其实org.apache.dubbo.common.timer.Timer接口定义了提交任务(一次性的)和停止时间轮的方法。
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
//入参非空校验
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
//校验最大可以接受的任务数量
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
//如果maxPendingTimeouts<=0,则不限制接受任务的数量
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
//启动时间轮(如果已启动则略过)
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
//计算任务的deadline
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
//将定时任务添加到任务队列中,HashedWheelTimeout是一个链表结构
//添加到队列中的HashedWheelTimeout会被定时器的HashedWheelBucket存放
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}
提交到任务队列的任务,会被存放到HashedWheelBucket链表中,同时过期任务的处理,以及tick的转动,这些都是Worker处理的。下面是Worker的run方法源码。
@Override
public void run() {
// Initialize the startTime.
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
//唤醒阻塞的在start()方法的线程
// Notify the other threads waiting for the initialization at start().
startTimeInitialized.countDown();
//循环执行,除非时间轮状态不是WORKER_STATE_STARTED了(stop了)
do {
//sleep到下一个tick
final long deadline = waitForNextTick();
if (deadline > 0) {
//获取tick对应格子的索引
int idx = (int) (tick & mask);
//移除被取消的任务
processCancelledTasks();
//取出对应格子中的任务链表
HashedWheelBucket bucket =
wheel[idx];
//将等待的任务添加到任务链表上
transferTimeoutsToBuckets();
// 过期执行格子中的任务(内部会把任务执行掉,不过是单线程的)
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
//时间轮被stop了,将没有处理完的任务添加到unprocessedTimeouts中,方便调用stop方法时获取
// Fill the unprocessedTimeouts so we can return them from stop() method.
for (HashedWheelBucket bucket : wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
//将处理定时任务队列中的任务取出,加入到unprocessedTimeouts队列中,方便调用stop方法时获取
for (; ; ) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}