为什么需要ConcurrentHashMap
在不需要线程安全的情况下,HashMap可以轻松满足我们的日常需求。但是HashMap是线程不安全的,在jdk1.8之前,多线程并发调用put方法,引发扩容,触发resize的过程,因为是链表的关系,甚至有几率形成死循环。(参考资料)。jdk1.8中,采用了复制的方法,而不是操作原链,不会再出现死循环的情况。
HashMap并不是并发容器,在并发环境必定存在性能和安全等方面问题。HashMap对应的线程安全容器HashTable或者java.util.Collections#synchronizedMap返回的线程安全容器,归根结底都只是用synchronized修饰获得的线程安全,性能并不高。
线程不安全的HashMap,效率低下的HashTable。因此,再jdk1.5中引入的j.u.c并发包中,出现了ConcurrentHashMap这个支持高并发的、线程安全的容器。
JDK1.7和1.8中ConcurrentHashMap的数据结构变化
JDK 1.7中的ConcurrentHashMap
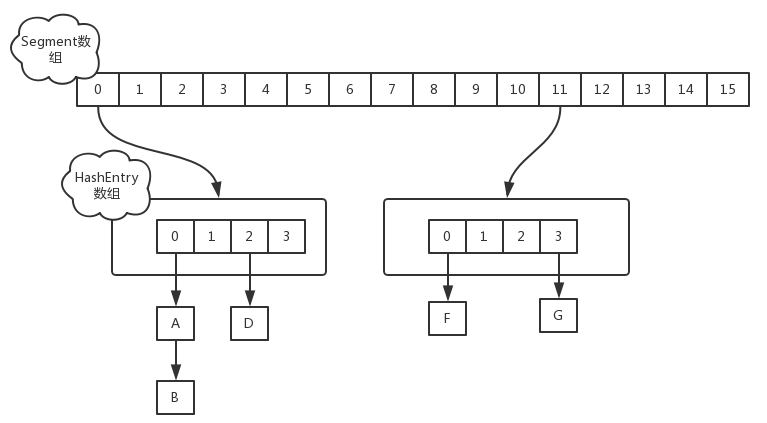
在JDK1.7中,ConcurrentHashMap的数据结构是:Segment数组+HashEntry链表数组。 Segment继承自ReentrantLock,提供加锁解锁功能。(将整个ConcurrentHashMap分成数段,也被称作分段锁/分拆锁)。HashEntry是一个链表,每个Segment维护一个HashEntry数组。
在jdk1.7中,定位一个元素需要两次Hash,第一次Hash定位到在哪个segment,第二次Hash定位在哪个HashEntry。在并发读写的时候,因为Segment自身支持加锁,所以只需要在元素所在的Segment上加锁即可,不会影响其他Segment的正常读写。
所以,理想情况下,ConcurrentHashMap最高可以支持到Segment数组长度的并发度,其并发能力相较于HashTable,获得了大大的提高。ConcurrentHashMap默认的并发度为16,用户可以设置并发度,ConcurrentHashMap会向上取大于等于当前数的最小二次幂(e.g.:16->16,17->32)。如果并发度设置的过小,会造成锁竞争频繁;如果并发度设置的过大,数据过于分散,CPU cache命中率会下降,从而引起程序性能下降。
ConcurrentHashMap在1.7中的扩容方式仍然是基于2的幂数倍扩容(方便复制转移元素)。但是ConcurrentHashMap的扩容是针对某个Segment的,而不是针对整个容器的。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry<K,V>[] table;
final float loadFactor;
}
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
JDK 1.8中的ConcurrentHashMap
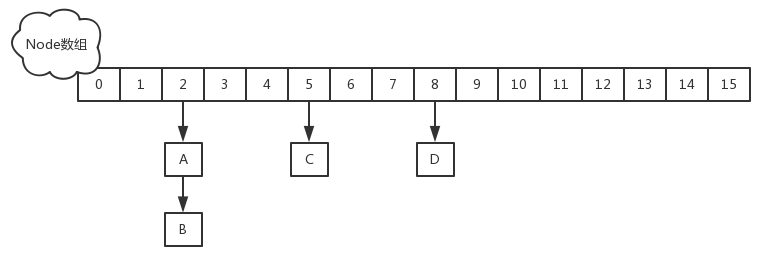
JDK1.8中的ConcurrentHashMap摒弃了分段锁的设计。在数据结构上采用数组+链表+红黑树的结构,和HashMap使用的数据结构是一样的。在线程安全方面,JDK1.8中的ConcurrentHashMap采用了 CAS + synchronized的设计,所以看起来ConcurrentHashMap看起来就像是一个优化版的线程安全的HashMap。
在ConcurrentHashMap中Node继承自Map.Entry,ConcurrentHashMap存储结构的基本单元。其自身是链表结构。HashMap的扩容和Hash冲突解决参考 https://russxia.github.io/2019/05/06/HashMap中的Hash冲突解决和扩容机制.html
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
JDK1.8中的ConcurrentHashMap中如何保证线程安全
前面提到了JDK1.8中的ConcurrentHashMap采用了 CAS + synchronized来保证线程安全。
在put元素时,首先会通过hash确定落到node数组的哪个index位置,然后判断index位置上是否为空,如果是空的,用cas的方式put元素,如果cas失败了,说明并发争抢了当前index位置。向已经存在元素的index位置添加元素,用synchronized锁住当前index,同步添加。
关于node节点的状态,有以下四种:
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算当前key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
//如果这次没有put成功,会重试
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//ConcurrentHashMap的初次put会做init操作
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果对应的node为空,以cas的方式put元素,如果成功,直接退出循环
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果tab[i]的hash值为MOVED,表明该链表正在进行transfer操作,当前线程先帮助进行扩容操作,然后put
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//锁住node节点,对节点下的链表/红黑树进行同步操作
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { //大于0说明当前node是一个可用的链表节点
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果当前key已经存在,判断是否新值替换旧值(根据传入的onlyIfAbsen决定),然后退出
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//如果下一个节点为空,直接put进去,然后退出
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
//继续遍历
}
}
//如果当前节点是一个树状结构,向树中插入一个元素
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//binCount是用来统计链表长度的
if (binCount != 0) {
//如果长度达到阈值,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//统计长度,检查时候需要扩容
addCount(1L, binCount);
return null;
}