基本概念
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-concepts.html#_index
基于elasticsearch-6.7.0版本
接近实时(near-realtime)
Elasticsearch是一个接近实时的搜索平台。Elasticsearch为document重新index的时候直到这个index变得可搜索,会有轻微的延迟(大概1s左右)。
集群(cluster)和节点(node)
cluster是一个或多个node的集合,cluster通过node保存全部的数据,提供联合索引和搜索能力。每个集群都有一个唯一的名字(默认为elasticsearch)。node节点通过自己的名字加入到对应的集群。 一个集群只有一个节点也是有效的。也可以有多个集群,但每个集群都要有它自己唯一的cluster name。
node(节点)是一个单独的服务器,是集群的一部分,负责存储数据,参与集群中的索引和搜索功能。和集群一样,node节点也需要一个唯一的标识符,默认是一个随机生成的uuid。node可以通过配置cluster name加入到特定的集群中。默认情况下,每个节点在安装时都会加入elasticsearch集群,这意味着,如果启动了多个node,且他们能互相发现(网络互通),它们将自动组成并加入到elasticsearch这个集群中来。
索引(index)、类型(type)和文档(document)
index(索引)是具有相似特征的document(文档)的集合,例如,你可以又消费者数据的索引,产品目录的索引、订单的索引等。索引有name标识(必须全部小写),并且这个name在索引对documents进行indexing, search, update, and delete操作时也会涉及到。
type [Deprecated in 6.0.0.Completely removed in 8.0.0.] 一个type是索引中的一个逻辑的种类/分区以便在相同索引中存储不同类型的document。现在不再能在一个index中创建多个type,整个type的概念都将在后续版本被移除。
document是索引信息的基本单位。例如,你可以有存储一个customer数据的document,存储一个product数据的document,存储一个order数据的document。document以json格式表示。
分片和副本(shards and replicas)
索引可以存储大量的数据,甚至超过单node硬件的限制。(所以需要分片和副本)
Elasticsearch能把一个Index拆分到多个Shard(分片)中,创建索引时,可以定义shard(分片)的数量。每个shard自身都是fully-functional(全功能的)、独立的索引,因此shard可以存储在集群中的任意node上。
sharding(分片)的两个重要理由:
- 支持水平的拆分/扩展
- 分布式并行地在shard上(可能多个shard)操作,因而提高吞吐量
shard的分布机制和document的聚合以支持搜索都由es管理,对用户完全透明。
集群环境中,某个shard/node可能会挂掉,为了保证failover,es允许用户为index的分片(shard)设置一个或多个副本(replica),称之为replica shards(副本分片)或者replicas(副本)。
replica的两个重要理由:
- 当某个node/shard宕掉时,依然高可用(high availability)。(注意保证在主Shard被复制时副本的 Shard不会被分配到相同的节点上。类似于hdfs的分布式文件系统,分片保证HA)
- 允许水平扩展搜索量/吞吐量,因为搜索可以在所有副本上并行执行。
总结: 每个索引都可以被拆分成多个shard,一个shard可以设置0个或多个副本(replica)。开启副本后,每个索引将有主分片(被复制的原始分片)和副分片(主分片的副本)。分片和副本的数量在创建索引时都能指定,索引创建后,可以任意地动态调整副本(replicas)的数量,可以通过_shrink和 _splitAPIs来改变一个已经存在的索引的shard数量。但是最好还是预先设计好合适的shards数量。
默认情况下,es中的索引有5个主分片和一个副本(5个主的shard+5个replica shard)。
ES update或者delete操作的流程
- 从旧文档构建 JSON
- 更改该 JSON
- 删除旧文档
- 索引一个新文档
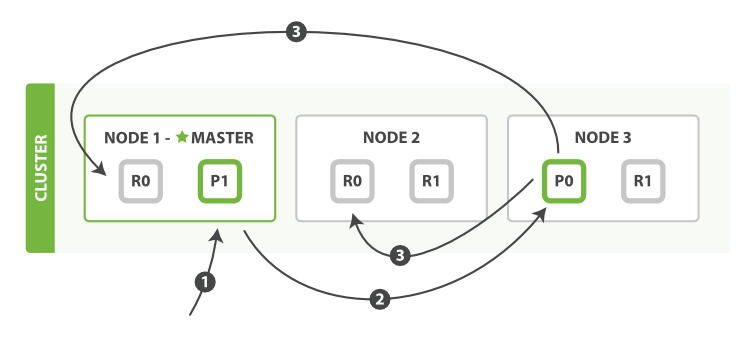
写操作的基本流程
以下是在主副分片和任何副本分片上面,成功新建、索引和删除文档所需要的步骤顺序:
- 客户端向
Node 1发送新建、索引或者删除请求(master node)。 - 节点使用文档的
_id确定文档属于分片P0。请求会被转发到Node 3,因为分片 0 的主分片目前被分配在Node 3上。 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功。
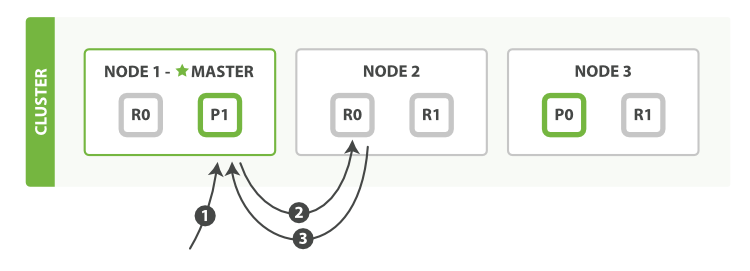
读操作的基本流程
以下是从主分片或者副本分片检索文档的步骤顺序:
- 客户端向
Node 1发送获取请求。 - 节点使用文档的
_id来确定文档属于分片P0。分片P0的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到Node 2。 Node 2将文档返回给Node 1,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
安装
前置要求: java8
下载es
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.tar.gz
启动es
cd elasticsearch-6.7.0/bin
./elasticsearch
启动日志:
[2019-04-03T14:56:44,929][DEBUG][o.e.a.ActionModule ] [sNvWT__] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security
[2019-04-03T14:56:45,263][INFO ][o.e.d.DiscoveryModule ] [sNvWT__] using discovery type [zen] and host providers [settings]
[2019-04-03T14:56:46,567][INFO ][o.e.n.Node ] [sNvWT__] initialized
[2019-04-03T14:56:46,569][INFO ][o.e.n.Node ] [sNvWT__] starting ...
[2019-04-03T14:56:46,842][INFO ][o.e.t.TransportService ] [sNvWT__] publish_address {127.0.0.1:9300}, bound_addresses {[::1]:9300}, {127.0.0.1:9300}, {127.94.0.2:9300}, {127.94.0.1:9300}
[2019-04-03T14:56:49,944][INFO ][o.e.c.s.MasterService ] [sNvWT__] zen-disco-elected-as-master ([0] nodes joined), reason: new_master {sNvWT__}{sNvWT__lQl6p0dMTRaAOAg}{i-RFiVStQOGNvqp-BrlRsQ}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=8589934592, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true}
[2019-04-03T14:56:49,952][INFO ][o.e.c.s.ClusterApplierService] [sNvWT__] new_master {sNvWT__}{sNvWT__lQl6p0dMTRaAOAg}{i-RFiVStQOGNvqp-BrlRsQ}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=8589934592, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true}, reason: apply cluster state (from master [master {sNvWT__}{sNvWT__lQl6p0dMTRaAOAg}{i-RFiVStQOGNvqp-BrlRsQ}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=8589934592, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true} committed version [1] source [zen-disco-elected-as-master ([0] nodes joined)]])
[2019-04-03T14:56:50,043][INFO ][o.e.h.n.Netty4HttpServerTransport] [sNvWT__] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}, {127.94.0.2:9200}, {127.94.0.1:9200}
[2019-04-03T14:56:50,043][INFO ][o.e.n.Node ] [sNvWT__] started
可以通过以下参数设置集群名称和节点名称:
./elasticsearch -Ecluster.name=my_cluster_name -Enode.name=my_node_nam
查看es信息:
➜ curl localhost:9200
{
"name" : "sNvWT__",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "iycBWcmjTE6-JY7YHmmmdA",
"version" : {
"number" : "6.7.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "8453f77",
"build_date" : "2019-03-21T15:32:29.844721Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}