开发环境准备
JDK 1.8
➜ [/Users/russ/workspace] java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
maven环境
➜ [/Users/russ/workspace] mvn -version
Apache Maven 3.6.0 (97c98ec64a1fdfee7767ce5ffb20918da4f719f3; 2018-10-25T02:41:47+08:00)
Maven home: /Users/russ/devtools/apache-maven-3.6.0
Java version: 1.8.0_191, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "mac os x", version: "10.13.6", arch: "x86_64", family: "mac"
IDE推荐使用ItelliJ IDEA。
创建maven项目
使用maven模版创建项目
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.6.1 \
-DgroupId=com.xzy.demo \
-DartifactId=flink-hello \
-Dversion=0.1 \
-Dpackage=com.xzy.demo \
-DinteractiveMode=false
关于mvn archetype:generate的相关参数,含义如下:
项目相关参数:
| 参数 | 含义 |
|---|---|
| groupId | 当前应用程序隶属的Group的ID |
| artifactId | 当前应用程序的ID |
| package | 代码生成时使用的根包的名字,如果没有给出,默认使用archetypeGroupId |
原型有关参数:
| 参数 | 含义 |
|---|---|
| archetypeGroupId | 原型(archetype)的Group ID |
| archetypeArtifactId | 原型(archetype)ID |
| archetypeVersion | 原型(archetype)版本 |
| archetypeRepository | 包含原型(archetype)的资源库 |
| archetypeCatalog | archetype分类,这里按位置分类有: ‘local’ 本地,通常是本地仓库的archetype-catalog.xml文件 ‘remote’ 远程,是maven的中央仓库 file://…’ 直接指定本地文件位置archetype-catalog.xml http://…’ or ‘https://…’ 网络上的文件位置 archetype-catalog.xml ‘internal’ 默认值是remote,local |
| archetypeVersion | 原型(archetype)版本 |
生成的代码如下:
➜ [/Users/russ/workspace] tree flink-hello
flink-hello
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── xzy
│ └── demo
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
编写第一个Flink程序
代码可以参照Flink的官方demo。
链接:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/datastream_api.html
以下是代码示例
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
//获得执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//定义数据源,这里是一个本地的9999端口的sock数据源
//对数据源做分组、开窗、聚合操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
//打印流数据 便于调试
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
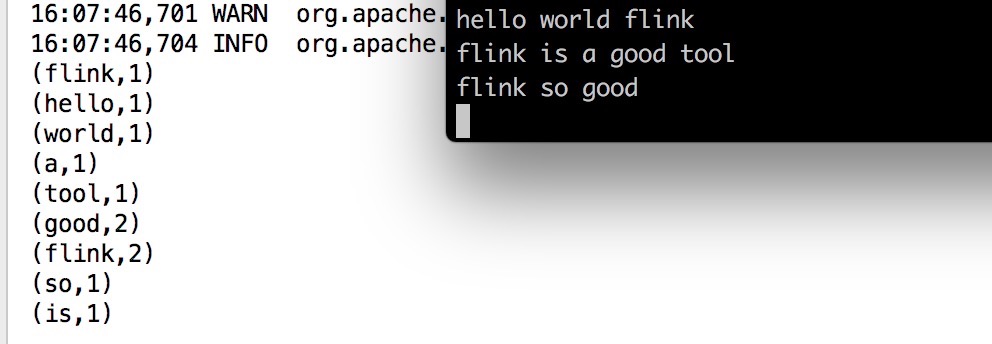
在9999端口上启动netcat,准备输入
nc -l 9999
运行WindowWordCount的main方法。
然后输入一些单词,回车,再输入新一行的单词。这些输入将作为示例程序的输入。如果要使得某个单词的计数结果大于1,请在5秒钟内重复输入相同的单词(如果5秒钟输入相同单词对你来说太快,请把示例程序中的窗口大小从5秒调大)。