什么是Hive?
Hive是一个构建在Hadoop上的数据仓库框架。 Hive定义了类似SQL的Hive QL,允许用户用类似SQL的方式进行操作。Hive把SQL查询转换为一系列在Hadoop集群上运行的map-reduce作业。
Hive的基本架构
Hive的基本组成:
- 用户接口:包挎CLI(shell命令行)、JDBC/ODBC,WebUI等
- 元数据存储:通常是存储在关系数据库如 mysql, derby中。元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
- 解释器、编译器、优化器、执行器:这些组件完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
- Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
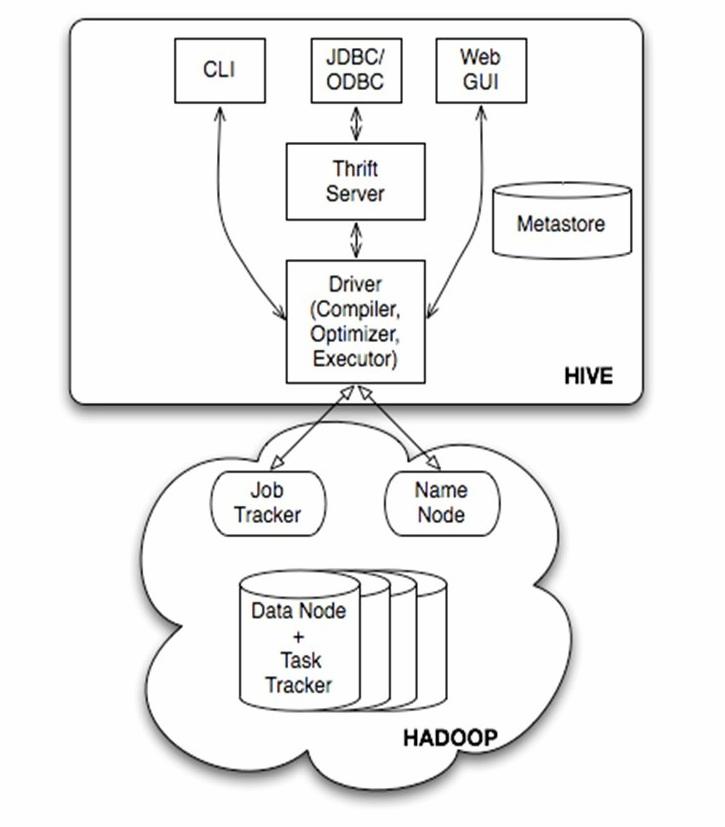
Hive的体系结构
如果以服务器方式运行Hive(hive –service hiveserver2),可以在应用程序中以不同的机制链接到服务器。Hive客户端和服务之前的联系如下图所示:
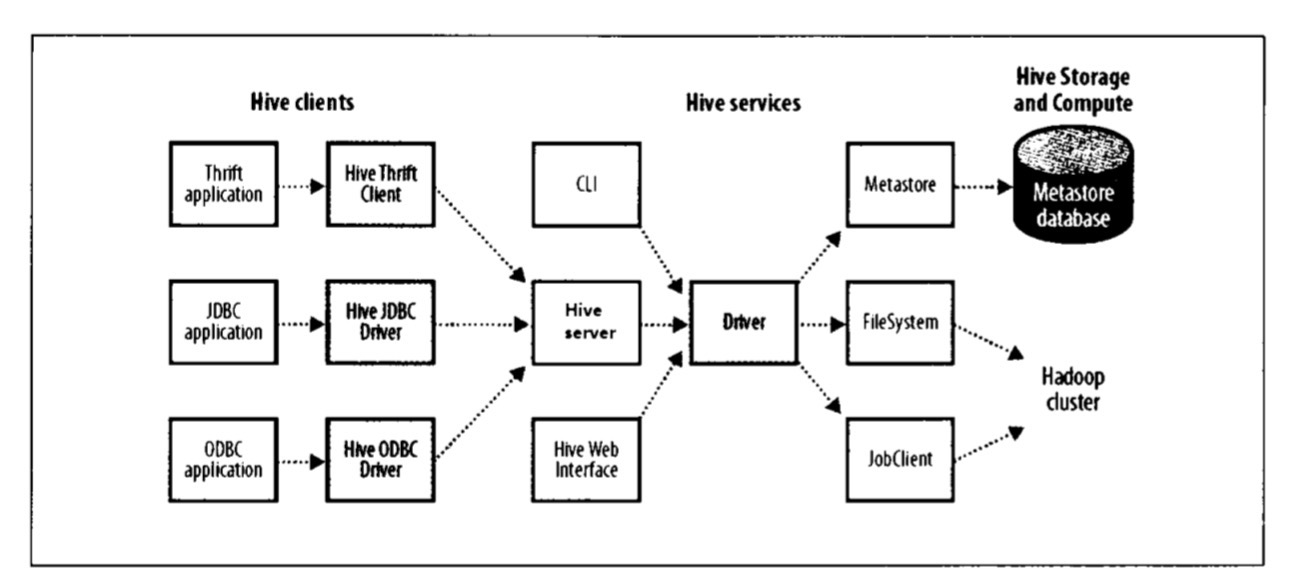
- Thrift客户端 Hive服务器提供Thrift服务的运行,因此任何支持Thrift的编程语言都可与之交互。
- JDBC驱动 Hive提供了Type4(纯Java)的JDBC驱动,定义在
org.apache.hadoop.hive.jdbc.HiveDriver类中。在以jdbc:hive2://host:port/dbname形式配置JDBC URI以后,Java应用程序可以在指定的主机和端口连接到另一个进程中运行的Hive服务器。 - ODBC驱动 Hive的ODBC驱动允许支持ODBC协议的应用程序连接到Hive
Metastore
metastore是Hive元数据的集中存放地。metastore包括两部分:服务和后台数据的存储。根据metastore存放的不同,Hive分为三种启动方式:内嵌模式(embedded metastore)、本地模式(local metastore)、远程模式(remote metastore)。
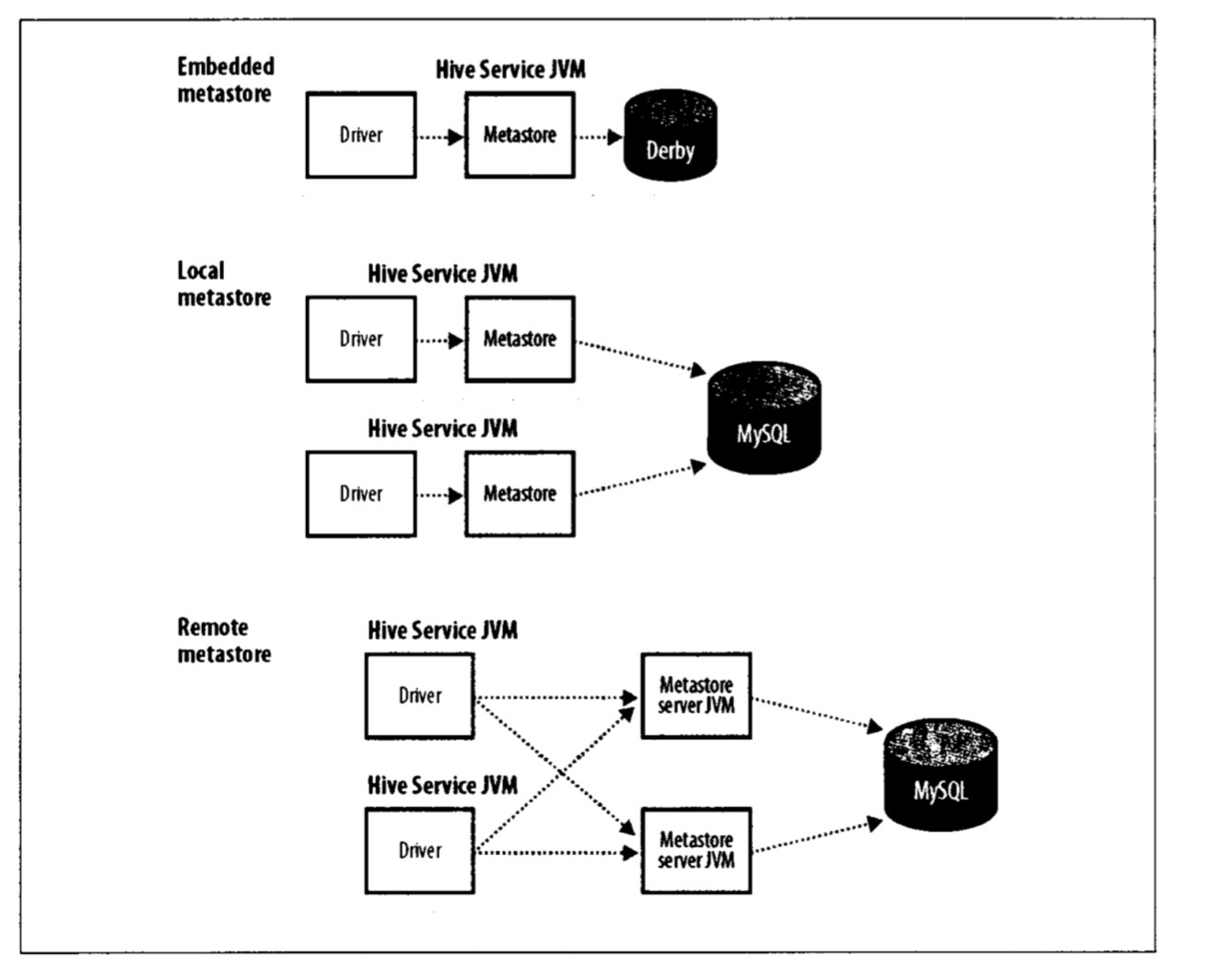
- 内嵌模式:使用内嵌的derby数据库,只能为metastore打开一个hive会话。
- 本地模式:为了支持多会话,使用一个独立的数据库来保存metastore。metastore服务和hive服务依然运行在同一个进程中,但连接的却是在另一个中运行的数据 库(可以在同一个机器上或在远程机器上)。
- 远程模式:一个或多个metastore服务器和hive服务运行在不同的进程中。这样一来,数据库层可以完全置于防火墙后,客户端不需要数据库凭据,从而提供了更好的管理性和安全性。(metastore和数据库在一侧,hive服务在一侧)
Hive和传统数据库对比
读时模式 vs 写时模式
在传统数据库里,表的模式是在数据加载时强制确定的。如果加载时发现不符合模式,则拒绝加载数据。因为数据在写入数据库时对照模式(schema)进行检查,所以这一模式有时也被称为”写时模式”(schema on write)。
Hive对数据的验证并不在加载数据时进行,而在查询时进行,这样的模式称为”读时模式”(schema on read)。因此对于Hive来说,数据加载仅仅是文件的复制或移动。
写时模式有利于提升查询的性能,但此时加载会消耗更多的时间。读时模式加载很快,但是查询会比较慢。
Hive的更新、事物
Hive从0.14版本开始支持事务和行级更新,但缺省是不支持的,需要一些附加的配置。要想支持行级insert、update、delete,需要配置Hive支持事务。 虽然支持,但Hive更适合于对非常大的不可变数据集进行批处理。因为本质上Hive是把HQL解释、编译、优化成一系列的map-reduce程序,然后执行。
What Is Hive
Hive is a data warehousing infrastructure based on Apache Hadoop. Hadoop provides massive scale out and fault tolerance capabilities for data storage and processing on commodity hardware.
Hive is designed to enable easy data summarization, ad-hoc querying and analysis of large volumes of data. It provides SQL which enables users to do ad-hoc querying, summarization and data analysis easily. At the same time, Hive's SQL gives users multiple places to integrate their own functionality to do custom analysis, such as User Defined Functions (UDFs).
What Hive Is NOT
Hive is not designed for online transaction processing. It is best used for traditional data warehousing tasks.
Hive的索引
Hive的索引,目的是提高hive表指定列的查询速度。在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括,索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。
在执行索引字段查询时候,首先额外生成一个MR job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs文件路径及偏移量,输出到hdfs上的一个文件中,然后根据这些文件中的hdfs路径和偏移量,筛选原始input文件,生成新的split,作为整个job的split,这样就达到不用全表扫描的目的。
目前Hive的索引分为两类:紧凑(compact)索引和位图索引(bitmap)。
紧凑索引存储每个值的HDFS块号,而不是存储文件内偏移量。因此存储不会占用过多的磁盘空间,且对于值被聚簇(clustered)存储于相近行的情况,索引仍然有效。
位图索引使用压缩的位集合(bitset)来高效存储具有某个特殊值的行。这种索引一般适合于具有较少取值可能的列(如性别或国别)。
Hive的数据类型
Numeric Types
- TINYINT (1-byte signed integer, from -128 to 127)
- SMALLINT (2-byte signed integer, from -32,768 to 32,767)
- INT/INTEGER (4-byte signed integer, from -2,147,483,648 to 2,147,483,647)
- BIGINT (8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
- FLOAT (4-byte single precision floating point number)
- DOUBLE (8-byte double precision floating point number)
- DOUBLE PRECISION (alias for DOUBLE, only available starting with Hive 2.2.0)
- DECIMAL
- Introduced in Hive 0.11.0 with a precision of 38 digits
- Hive 0.13.0 introduced user-definable precision and scale
- NUMERIC (same as DECIMAL, starting with Hive 3.0.0)
Date/Time Types
- TIMESTAMP (Since 0.8.0)
- DATE (Since 0.12.0)
- INTERVAL (Since 1.2.0)
String Types
- STRING
- VARCHAR (Since 0.12.0)
- CHAR (Since 0.13.0)
Misc Types
- BOOLEAN
- BINARY (Since 0.8.0)
Complex Types
- arrays: ARRAY
(Note: negative values and non-constant expressions are allowed as of Hive 0.14.) - maps: MAP<primitive_type, data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
- structs: STRUCT<col_name : data_type [COMMENT col_comment], …>
- union: UNIONTYPE<data_type, data_type, …> (Since 0.7.0.)