Sharding-JDBC Lexer源码分析
Lexer中的Toekn
Lexer在Sharding-JDBC中的主要作用是顺序解析sql,将字符串解析成一个个Token(包含词法类型、词法字面量、sql字符串中结束位置等信息)。
@RequiredArgsConstructor
@Getter
public final class Token {
//词法类型
private final TokenType type;
//字面量
private final String literals;
//在sql字符串中的偏离位置
private final int endPosition;
}
其中,词法类型主要分为以下几种:
- DefaultKeyword-关键字类型:SQL中一些有特殊意义的关键字,e.g.:SCHEMA、TABLE、CREATE、SELECT。
- Literals-字面量:包含INT, FLOAT, HEX, CHARS, IDENTIFIER, VARIABLE等类型。
- Symbol-符号类型:各类符号,e.g.:’+’、’;’、’(‘、’«‘等等
- Assit-辅助类型:目前之定义了END, ERROR两种类型
下面是一段Sharding-JDBC中的一段JUnit测试方法。包括了我们上面提到的几种类型
private void assertNextTokenForNumber(final String expectedNumber, final TokenType expectedTokenType) {
Lexer lexer = new Lexer(String.format("SELECT * FROM XXX_TABLE WHERE XX=%s AND YY=%s", expectedNumber, expectedNumber), dictionary);
LexerAssert.assertNextToken(lexer, DefaultKeyword.SELECT, "SELECT");
LexerAssert.assertNextToken(lexer, Symbol.STAR, "*");
LexerAssert.assertNextToken(lexer, DefaultKeyword.FROM, "FROM");
LexerAssert.assertNextToken(lexer, Literals.IDENTIFIER, "XXX_TABLE");
LexerAssert.assertNextToken(lexer, DefaultKeyword.WHERE, "WHERE");
LexerAssert.assertNextToken(lexer, Literals.IDENTIFIER, "XX");
LexerAssert.assertNextToken(lexer, Symbol.EQ, "=");
LexerAssert.assertNextToken(lexer, expectedTokenType, expectedNumber);
LexerAssert.assertNextToken(lexer, DefaultKeyword.AND, "AND");
LexerAssert.assertNextToken(lexer, Literals.IDENTIFIER, "YY");
LexerAssert.assertNextToken(lexer, Symbol.EQ, "=");
LexerAssert.assertNextToken(lexer, expectedTokenType, expectedNumber);
LexerAssert.assertNextToken(lexer, Assist.END, "");
}
Sharding-JDBC是支持多种数据库的,在词法上不同数据库的词法略有不同。例如describe是mysql支持,Oracle不支持的关键字。
Sharding-JDBC针对不同的数据库,有自己一套dialect的KeyWord。
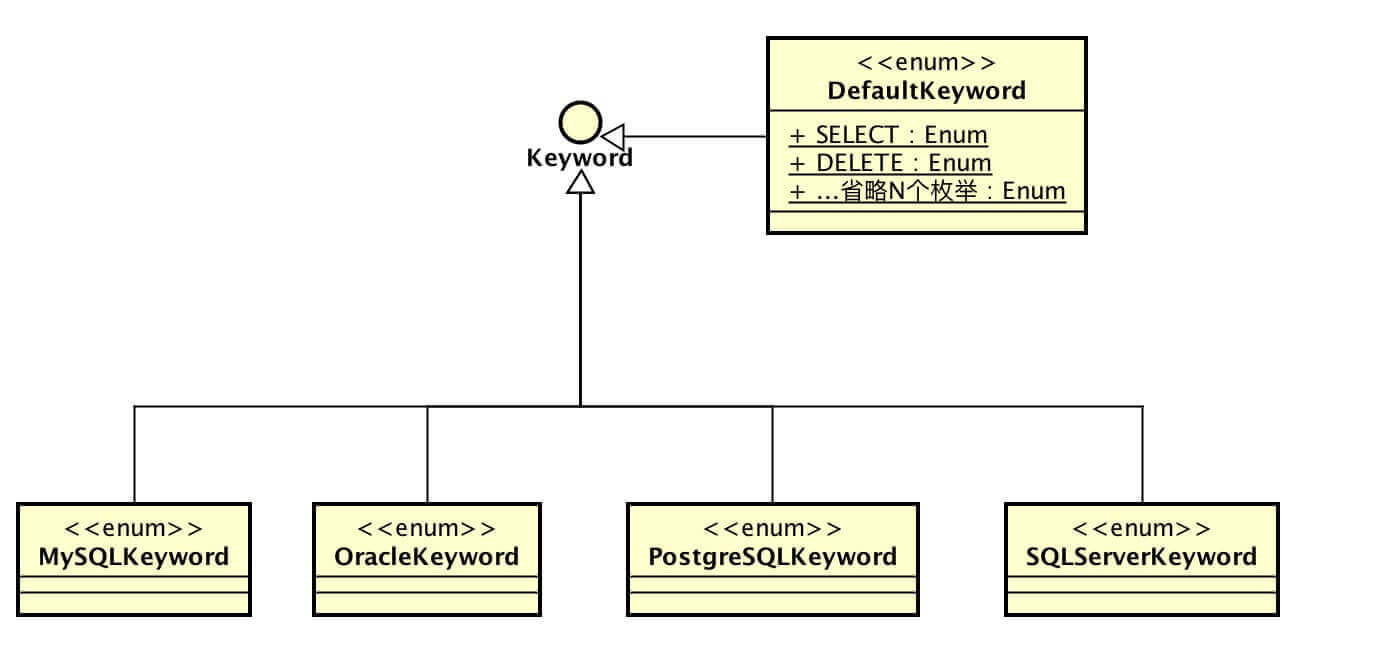
同理,针对不同的数据库,Sharding-JDBC使用的词法解析器也是不同的,如MySQL的词法解析器:MySQLLexer,Oracle的词法解析器OracleLexer。在创建MySQL时,会加载DefaultKeyWord和MySQLKeyword。
Dictionary的构造方法
public Dictionary(final Keyword... dialectKeywords) {
fill(dialectKeywords);
}
private void fill(final Keyword... dialectKeywords) {
//加载默认的关键字
for (DefaultKeyword each : DefaultKeyword.values()) {
tokens.put(each.name(), each);
}
//加载特定的关键字
for (Keyword each : dialectKeywords) {
tokens.put(each.toString(), each);
}
}
MySQLLexer
public final class MySQLLexer extends Lexer {
//加载mysql的关键字
private static Dictionary dictionary = new Dictionary(MySQLKeyword.values());
public MySQLLexer(final String input) {
super(input, dictionary);
}
@Override
protected boolean isHintBegin() {
return '/' == getCurrentChar(0) && '*' == getCurrentChar(1) && '!' == getCurrentChar(2);
}
@Override
protected boolean isCommentBegin() {
return '#' == getCurrentChar(0) || super.isCommentBegin();
}
@Override
protected boolean isVariableBegin() {
return '@' == getCurrentChar(0);
}
}
Lexer解析SQL
Lexer类中解析的核心方法是io.shardingsphere.core.parsing.lexer.Lexer#nextToken。
@RequiredArgsConstructor
public class Lexer {
//输入的sql
@Getter
private final String input;
//词典,里面包含了各种关键字
private final Dictionary dictionary;
//当前解析位置的偏移量
private int offset;
//当前解析出的Token
@Getter
private Token currentToken;
/**
* Analyse next token.
*/
public final void nextToken() {
//部分内容跳过解析
skipIgnoredToken();
if (isVariableBegin()) { //解析变量
currentToken = new Tokenizer(input, dictionary, offset).scanVariable();
} else if (isNCharBegin()) { //nchar、nvarchar类型解析
currentToken = new Tokenizer(input, dictionary, ++offset).scanChars();
} else if (isIdentifierBegin()) { //标识符解析(包含关键字)
currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier();
} else if (isHexDecimalBegin()) { //16进制数字解析
currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal();
} else if (isNumberBegin()) { //数字解析(整型、浮点型)
currentToken = new Tokenizer(input, dictionary, offset).scanNumber();
} else if (isSymbolBegin()) { //符号解析(,+*{}()#>~!^等等)
currentToken = new Tokenizer(input, dictionary, offset).scanSymbol();
} else if (isCharsBegin()) { //字符串解析
currentToken = new Tokenizer(input, dictionary, offset).scanChars();
} else if (isEnd()) { //判断是否到达末尾
currentToken = new Token(Assist.END, "", offset);
} else { //若全未命中,解析出错,抛出异常
throw new SQLParsingException(this, Assist.ERROR);
}
//偏移量调整
offset = currentToken.getEndPosition();
}
/**
* 跳过忽略的词法标记
* 1. 空格
* 2. SQL Hint
* 3. SQL 注释
*/
private void skipIgnoredToken() {
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
while (isHintBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipHint();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
while (isCommentBegin()) {
offset = new Tokenizer(input, dictionary, offset).skipComment();
offset = new Tokenizer(input, dictionary, offset).skipWhitespace();
}
}
..省略..
..省略..
..省略..
}
各类解析大同小异,下面以解析标识符为例。
/**
* scan identifier.
*
* @return identifier token
*/
public Token scanIdentifier() {
//如果是以`开头的,肯定是一个字面量
if ('`' == charAt(offset)) {
int length = getLengthUntilTerminatedChar('`');
return new Token(Literals.IDENTIFIER, input.substring(offset, offset + length), offset + length);
}
int length = 0;
while (isIdentifierChar(charAt(offset + length))) {
length++;
}
String literals = input.substring(offset, offset + length);
//如果是order/group这样的关键字,特殊处理
if (isAmbiguousIdentifier(literals)) {
return new Token(processAmbiguousIdentifier(offset + length, literals), literals, offset + length);
}
//是否是关键字,如果不是,返回字面量类型。
return new Token(dictionary.findTokenType(literals, Literals.IDENTIFIER), literals, offset + length);
}
//关键字如果包含字面量,返回关键字,否则返回给定的默认类型defaultTokenType。
TokenType findTokenType(final String literals, final TokenType defaultTokenType) {
String key = null == literals ? null : literals.toUpperCase();
return tokens.containsKey(key) ? tokens.get(key) : defaultTokenType;
}
Sharding-JDBC是如何使用Lexer的
Sharding-JDBC通过简单工程模式,通过LexerEngineFactory.newInstance方法,产生一个携带特定语法解析的LexerEngine。
public static LexerEngine newInstance(final DatabaseType dbType, final String sql) {
switch (dbType) {
case H2:
case MySQL:
return new LexerEngine(new MySQLLexer(sql));
case Oracle:
return new LexerEngine(new OracleLexer(sql));
case SQLServer:
return new LexerEngine(new SQLServerLexer(sql));
case PostgreSQL:
return new LexerEngine(new PostgreSQLLexer(sql));
default:
throw new UnsupportedOperationException(String.format("Cannot support database [%s].", dbType));
}
}