基于SnowFlake的分布式主键生成器
常见的分布式主键生成策略
UUID
UUID(Universally Unique Identifier)主要优点是:
- 性能高,本地生成,不需要网络开销;
主要缺点:
- 太长不易存储,也不适合做MySQL.InnoDB引擎的主键(索引开销大大增大)
- 基于MAC地址生成,信息不安全
类SnowFlake方案
这个也是我们这一小节所讲述的方案,基于Twitter的SnowFlake(雪花算法)。
主要优点:
- 第2位到42位是时间戳,所以整个ID趋势自增
- 不依赖与第三方服务(数据库或其他服务),本地生成ID,性能也很高
- 可以自己定制生成方案,灵活方便
- 生成的ID可以解读(生成时间,生成机器,生成的序列号)
主要缺点:
- 强依赖与部署机器的始终,如果发生时间回拨,服务可能不可用或生成的ID重复
基于数据库等方案的发号器策略
以MySQL为例,设置主键自增,请求生成ID时使用下面的SQL生成ID。
begin;
REPLACE INTO uuid (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
此方案的优点:
- 实现简单,利用现有的数据库等工具,实现成本小
- ID号可以满足单调递增,满足某些特殊业务的需求。
缺点:
- 强依赖于DB等工具。如果DB服务不可用(DB宕机,主从切换),则无法生成ID或生成的ID重复。
- 性能瓶颈依赖于DB的读写性能。
SnowFlake简介
SnowFlake是Twitter推出的,64位趋势自增ID算法,数据划分如下:
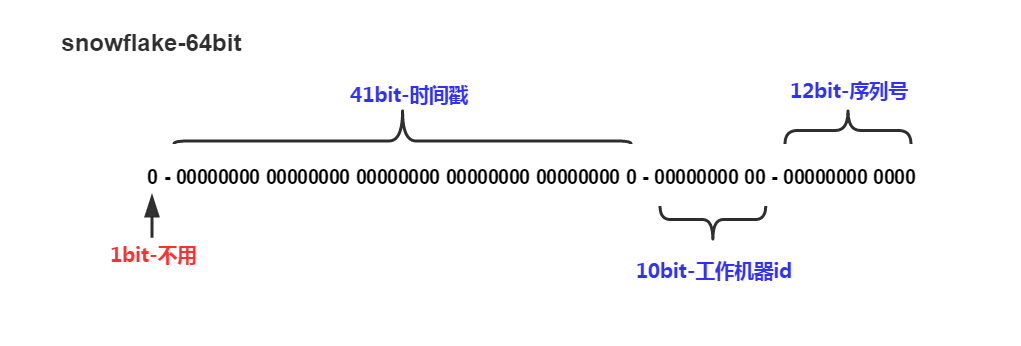
说明
- 第一位保留位,暂时不用
- 41位的时间戳,时间戳是当前时间到1970年1月1日的毫秒数,整好41位。所以SnowFlake的时间戳占了41位
public static void main(String[] args) {
Long now = System.currentTimeMillis();
System.out.println(now);
System.out.println(Long.toBinaryString(now));
Date date = new Date(now);
System.out.println(date);
}
1527493393814
10110001110100101101100110111110110010110
Mon May 28 15:43:13 CST 2018
- 10位的工作机器ID,2^10=1024,表示最多可以部署1024台机器用于生成ID
- 12位的序列号,2^12=4096,表示每台机器每ms最多可以生成4096个key
Sharding-JDBC中的SnowFlake的实现
Sharding-JDBC提供了一个基于SnowFlake算法的默认的分布式主键生成器。
下面是按照Sharding-JDBC中默认主键生成器io.shardingjdbc.core.keygen.DefaultKeyGenerator的Java代码。
import com.google.common.base.Preconditions;
/**
* 分布式ID生成器
* 64bit
* 第一位默认为0(不适用)+41位时间戳+10位工作机器ID()+12位序列号
* 强依赖于系统时间,如果时间回拨(机器同步时间时、2017年闰秒等情况下可能发生),直接抛出异常
*/
public class SnowFlakeIDGenerator {
/**
* 起始的时间戳,2018-1-1 00:00:00:000
*/
private static final long START_TIME = 1514736000000L;
/**
* workId可以占的位数
*/
private static final long WORKER_ID_BITS = 10L;
/**
* 序列号占用的位数
*/
private static final long SEQUENCE_BITS = 12L;
/**
* workId需要左移的位数
*/
private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS;
/**
* 时间戳需要左移的位数
*/
private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS;
/**
* 最小的workId
*/
private static final long MIN_WORKER_ID = 0L;
/**
* 最大的workId
*/
private static final long MAX_WORKER_ID = 1L << WORKER_ID_BITS;
/**
* 最大序列上限
*/
private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1;
/**
* 可以考虑使用zk的持久顺序节点特性设置workId
* 也可以通过启动参数指定,或者考虑使用机器的IP(截取后10位)
*/
private Long workerId;
/**
* 当前序列号
*/
private long sequence;
/**
* 上次的生成器时间,起初设置为开始时间
*/
private long lastTime = START_TIME;
/**
* 可以通过spring的构造器注入bean
*
* @param workerId 工作机器ID
*/
public SnowFlakeIDGenerator(long workerId) {
Preconditions.checkArgument(workerId >= MIN_WORKER_ID && workerId <= MAX_WORKER_ID, "illegal workerId : %s", workerId);
this.workerId = workerId;
}
public synchronized Number generateKey() {
long currentMillis = System.currentTimeMillis();
// TODO: 2018/5/18 短毫秒数内,考虑自旋方式;长毫秒的话,考虑使用备用workId
Preconditions.checkState(lastTime <= currentMillis, "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastTime, currentMillis);
if (lastTime == currentMillis) {
//sequence最大不能超过SEQUENCE_MASK,如果超过了,等1ms进入下一个序列
if (0L == (sequence = ++sequence & SEQUENCE_MASK)) {
currentMillis = waitNextMillis(lastTime);
}
} else {
sequence = 0;
}
lastTime = currentMillis;
//计算生成的key,左移22位,其中前12位是workId,后10位是序列化(序列号最大就是10位)
return ((currentMillis - START_TIME) << TIMESTAMP_LEFT_SHIFT_BITS) | (workerId << WORKER_ID_LEFT_SHIFT_BITS) | sequence;
}
private long waitNextMillis(final long lastTime) {
long time = System.currentTimeMillis();
while (time <= lastTime) {
time = System.currentTimeMillis();
}
return time;
}
}
如果同一台实例需要部署多个ID生成器的话,注入不同的workId即可。
上述方案以及可以改进的地方
- workId可以考虑使用zk的持久顺序节点,在注册bean时向zk注册一个持久顺序节点,拿到当前的workId,销毁bean的时候销毁当前节点。
- 如果发生时间回拨的话,当前方案的处理方式是直接抛出异常。
如果发生时间回拨,时间短的话(10ms左右),可以考虑通过自旋的方式,等待生成新的ID。如果回拨时间过长,考虑更换workId(这回导致精度有一定的降低)。 - 极端情况,回拨时间很长,例如时间从2018年5月28日回拨回2018年5月27日,如果服务重启,workId占用相同,极有可能会生成重复ID。
- 会长生大量偶数,数据不均匀。因为序列是从0开始计数的,每过1ms,序列被重置。在请求量不是很大的情况,生成的ID尾号0占比例较大。这样的ID不适合做分库分表。